解包QQ CustomFace.db文件 - 微软 Compound File Binary
至今,腾讯QQ版本号已经达到了9.0+,这个版本直接放弃了对自定义表情分组的支持,并且没有做任何的向后兼容。 而对于已经停止维护的 QQLite 和 TIM,这些版本的自定义表情功能导出功能基本无法使用,导出的eif文件是损坏的。 也就是说,用户必须自己想办法来导出珍藏十几年的祖传表情包了。
阅读完本篇文章,你将了解到我是如何尝试解析用于保存自定义表情的 CustomFace.db 文件的,文章结尾提供了一个可以在线解包并导出自定义表情的网站。
TL;DR:地址是 https://qqemote.unlucky.ninja/
Compound File Binary 格式
每次TIM的表情包突然被无故清空,我都会尝试重新导入现有表情包,而在文件对话框里,会发现有一个CustomFace.db文件可供选择。搜索一番后,了解到这个文件是微软的 Compound File Binary 格式,是 COM Structured Storage 的
一种。CustomFace.db 文件本身没有做加密。
Compound File Binary 简而言之就是一个头文件定义,基于FAT格式的扩展,将二进制文件划分为一个个片区,其中有文件内容本身的区块(划分为固定长度),用于索引其它类型区块的区块(用于将内容区块关联为完整的文件),用于索引索引区块的区块(自身以类似链表的形式关联),还有用于保存目录结构和文件信息的区块。
大致形式可以参考以下图片:
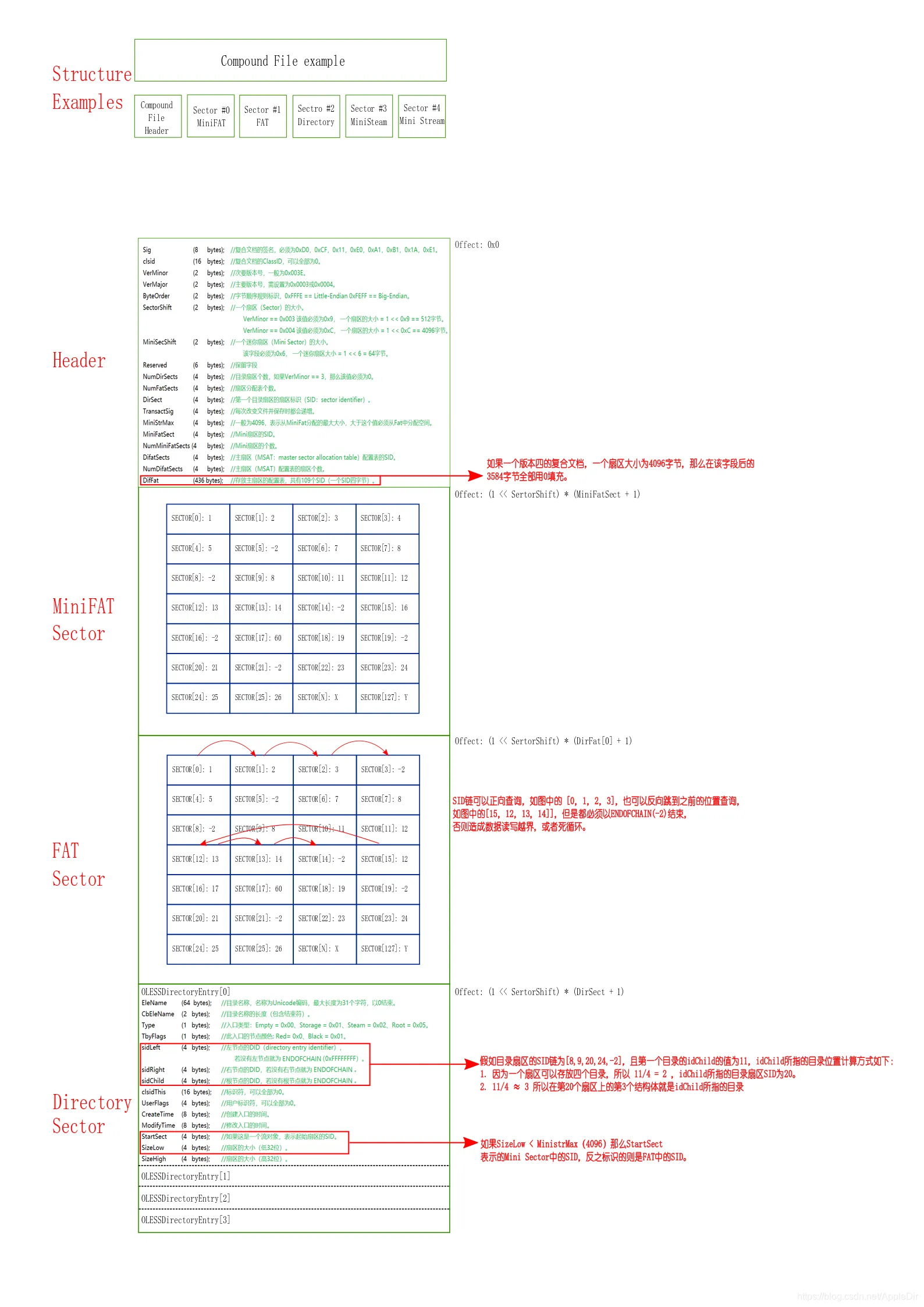 图片出处:https://bbs.kanxue.com/thread-254060.htm
图片出处:https://bbs.kanxue.com/thread-254060.htm
官方文档可以在 https://learn.microsoft.com/en-us/openspecs/windows_protocols/ms-cfb/53989ce4-7b05-4f8d-829b-d08d6148375b 浏览。
文件读取
首先要解决二进制文件读取的问题,虽然原生可以用file/blob或流式api读取, 但如果有一个可以通过指定字段大小来解析的库还是更方便些。 在 npm 和 github 搜索二进制文件读取相关关键词,binary-parser 看起来是个合理的选择(其似乎还有另一个实现 binopsy 但好像并未发布包,难以使用)
但然后我就看到了 binspector, 使用 Typescript,声明式定义,看起来更up-to-date,虽然没什么star,就试试它吧。
https://observablehq.com/ 几乎是我的无构建前端 playground 首选,响应式更新(非深层)非常方便。 缺点是不支持 Typescript 语法,不过如果变量是其它块的导出,或者是浏览器全局变量,还是有一定的类型智能提示。
为了解决 Typescript 支持问题,我使用了 esbuild 进行转译,transform() 的选项为
{
loader: 'ts',
format: 'iife',
globalName: 'defs', // 模块导出的名称,后面要用到
tsconfigRaw: {
compilerOptions: {
target: 'es2021', // 使转译结果包含 TS 自身对 decorator 的实现
},
},
}然后通过 Function 对 js 字符串求值,将模块导出结果返回,可从中引用定义的类。
const result = (new Function('binspector', headerBinaryMeta.code+';return defs;'))(binspector)
binread(new BinaryReader(file, BinaryCursorEndianness.LittleEndian), result.Header)当然如果你不是为了在浏览器中实时转译typescript,就没必要进行上面的操作
在识别完文件头后,需要寻址各类区块,我编写了一系列寻址函数,对应各个区块, 并对索引的寻址结果进行增量缓存,因为目录顺序是不固定的,难免会在各个区块反复跳转。 篇幅较长就不贴在这里了
demo 可以在这里找到 https://observablehq.com/d/6566626f9376fb6a
独立包版本在 https://github.com/UnluckyNinja/cfb-reader
在线工具网站
这部分没什么需要特别注意的,前端页面使用了nuxt+unocss来快速开发,部署在Cloudflare的免费静态托管Pages上。 读取完的文件通过fflate在浏览器中导出为压缩包。加入了一些花哨的彩虹渐变效果点缀。
不足之处是,由于是完全读取完文件再一起导出,内存占用非常大,500MB的文件可能要有接近3倍的占用量,或许边读取边压缩会更好一些?